Human Takeover Might be Worse than AI Takeover
Citations
11th January 2025Last update: 20th May 2025

This is a rough research note – we’re sharing it for feedback and to spark discussion. We’re less confident in its methods and conclusions.

Summary
Some are concerned that future AI systems could take over the world.1 We think that’s a serious risk but are also worried that AI could enable a human or a small group of humans to take over.
Suppose a human used AI to take over the world. Would this be worse than AI taking over? I think plausibly:
- In expectation, future AI systems will better live up to human moral standards than a randomly selected human. Because:
- Humans fall far short of our moral standards.
- Current models are much more nice, patient, honest and selfless than humans.
- Though future AI systems will have much more agentic training for economic output, and a smaller fraction of HHH training,2 which could make them less nice.
- Humans are "rewarded" for immoral behaviour more than AIs will be.
- Humans evolved under conditions where selfishness and cruelty often paid high dividends, so evolution often "rewarded" such behaviour. And similarly, during lifetime learning humans often benefit from immoral behaviour.
- But we'll craft the training data for AIs to avoid this, and can much more easily monitor their actions and even their thinking. Of course, this may be hard to do for superhuman AI, but bootstrapping might work.
- However, we are not considering a random human or a random AI: we’re considering an AI or human that decided to take over, and they are likely less moral than average.
- Conditioning on takeover happening makes the situation much worse for AI, as it suggests our alignment techniques completely failed. Though it’s possible that we partially succeeded in instilling our desired values in AI, but failed to instill an aversion to pursuing those values via excessive power-seeking.
- Conditioning on takeover also makes things much worse for the human. There's massive variance in how kind humans are, and those willing to take over are more likely to have dark triad traits. Humans may be vengeful or sadistic, which seems less likely for AI.
- AI will be more competent, so better at handling tricky dynamics like simulations, acausal trade, the vulnerable world hypothesis (VWH), and threats. (Though a human who followed AI advice could handle these equally well.)
Overall, I’m honestly leaning towards thinking AI takeover would be less bad than human takeover.

AI systems are nicer than humans in expectation
Humans don’t come close to living up to our moral standards.
By contrast, today’s AIs are really nice and ethical. They’re humble, open-minded, cooperative, and kind. Yes, they care about some things that could give them instrumental reasons to seek power (e.g. being helpful, human welfare), but their values are great.
The above is no coincidence. It falls right out of the training data.
- Humans were rewarded by evolution for being selfish whenever they could get away with it. So humans have a strong instinct to do that.
- Humans are rewarded by within-lifetime learning for being selfish. (Culture does increasingly well to punish this, and people have got nicer. But many subtler selfish behaviours are still reinforced during humans’ lifetimes.)
- AI systems are pre-trained on data which includes selfishness, malevolence, etc. But during the RLHF phase, AIs are only ever rewarded for appearing nice and helpful. We don’t reward them for selfishness. As AIs become superhuman there’s a risk we do increasingly reward them for tricking us into thinking they’ve done a better job than they have. But compared to evolution, we’ll be way more able to constantly monitor them during training and exclusively reward good behaviour. Evolution wasn’t even trying to reward only good behaviour!
- Lifetime learning is a more tricky comparison: society does try to monitor people and only reward good behaviour. But we can’t see people’s thoughts and can’t constantly monitor their behaviour, so AI training will do a much better job at making AIs nice at this stage, too.
- What’s more, we’ll just spend loads of time rewarding AIs for being ethical and open minded and kind. Even if we sometimes reward them for bad behaviour, the quantity of reward for good behaviour is something unmatched in humans (evolution or lifetime).
- Note: this doesn’t mean AIs won’t seek power. Humans seek power a lot! And especially when AIs are superhuman, it may be very easy for them to get power.
So humans live up to human moral standards less well than AIs today, we can see why that is with reference to the training data, and that trend looks set to continue (though there’s a big question mark over how much we’ll unintentionally reward selfish superhuman AI behaviour during training).

Conditioning on AI actually seizing power
Ok, that feeds into my prior for how ethical or unethical I expect humans to be compared to AI. I expect AI to be way better. But, crucially, we need to condition on takeover. I’m not comparing the average human to the average AI. I’m comparing the average human-that-would-actually-seize-power to the average AI-that-would-seize-power.
This makes a difference. Directionally, I think it pushes towards being more concerned about AI. Why is that?
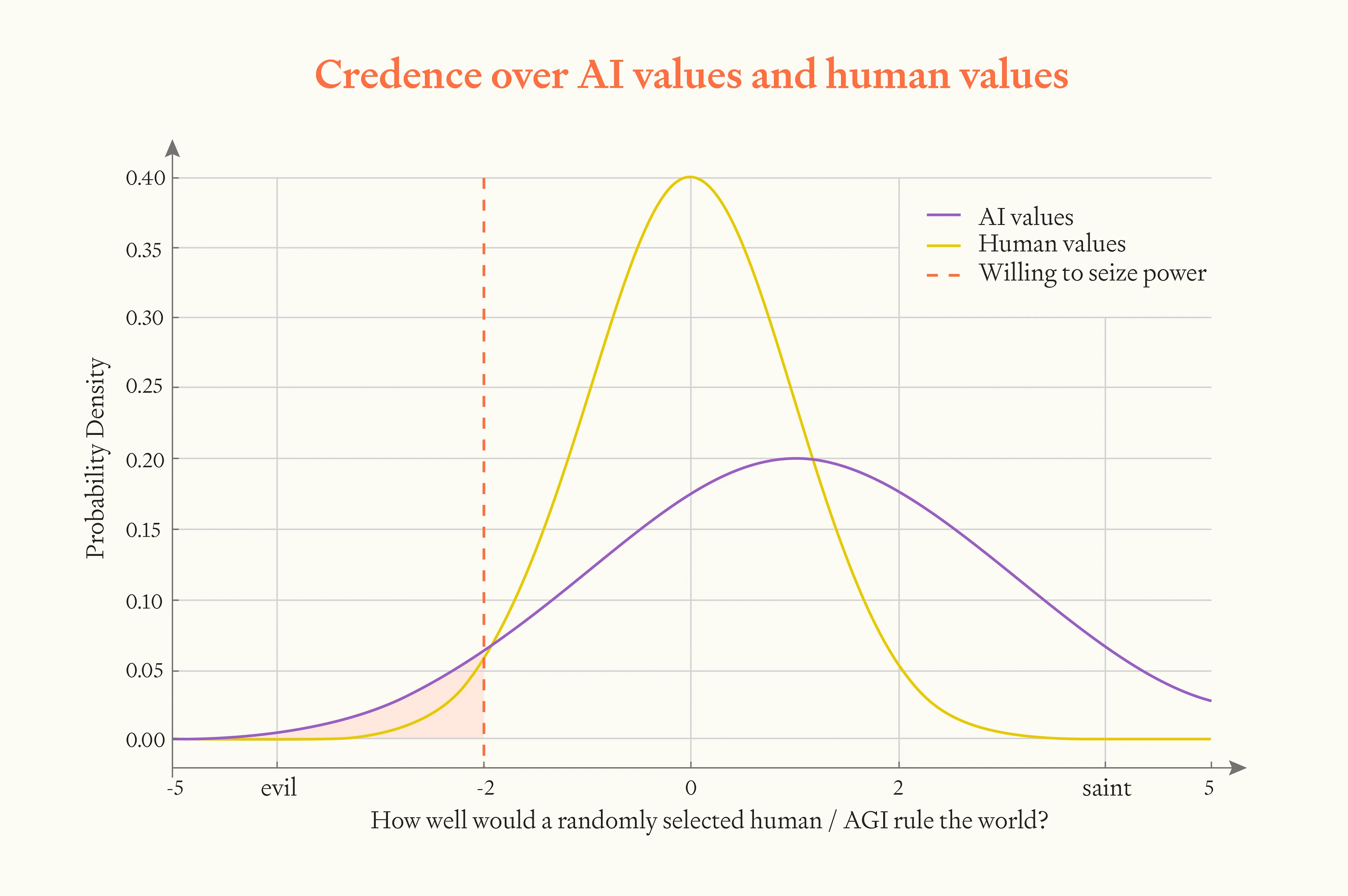
- We know a fair bit about human values. While I think humans are not great on average, we know about the spread of human values. We know most humans like normal human things like happiness, games, love, pleasure, and friendships (though some humans want awful things as well.) This maybe means the variance of human values isn’t that big: we can imagine having some credence over how nice a randomly selected person will be, represented by a probability distribution, and maybe the variance of the distribution is narrow.
- By contrast, we know a lot less about what future AI systems’ values will be. Like I said above, I expect them to be better (by human standards) than an average human’s values. But there’s truly massive uncertainty here. Maybe AI will care about some alien stuff that seems totally wacky to humans. We could represent this through our credence over AI’s values having a higher variance.
- When we condition on AI or human takeover, we’re conditioning on the AI/human having much worse values than our mean expectation. Even if AI systems have better values in expectation, it might be that after conditioning on this they have worse values (because of the bigger variance – see graph).
- In the graph, I’ve placed an orange line to represent ‘how bad’ your values would need to be to seize power. The way I’ve done it, an AI that seized power would use the cosmic endowment less well in expectation than a human who seized power.
Image
Actually, this ‘orange line’ is not quite the right way to think about it. Whether you seize power depends more on your deontological drive to cooperate and respect property rights and the law and freedom, and only somewhat on your long-term goals. All consequentialists want to take over! So whether you take over is more a question of corrigibility vs consequentialism than a question of how good your consequentialist values are.
- When we condition on AI takeover, we’re primarily conditioning on the ‘corrigible’ part of training to have failed. That probably implies the “give the AI good values” part of training has also gone less well, but it seems possible that there are challenges to corrigibility that don’t apply to giving AI good values (e.g. the MIRI-esque “corrigibility is unnatural”).
- So AIs taking over is only a moderate update towards them having worse values, even though it's a strong update against corrigibility/cooperativeness.
- This is a reason to be a bit less concerned about AI takeover than we would otherwise be.
Another reason that I’m not as concerned as the graph above would suggest is that I just don’t buy that AI will care about alien stuff. The world carves naturally into high-level concepts that both humans and AI latch onto. I think that’s obvious on reflection, and is supported by ML evidence. So I expect AI will care about human-understandable stuff. And humans will be trying hard to make AI systems that are that stuff that’s good by human lights, and I think we’ll largely succeed. Yes, AI systems may reward seek and they may extrapolate their goals to the long-term and seek power. But I think they’ll be pursuing human-recognisable and broadly good-by-human-lights goals.
- There’s some uncertainty here due to ‘big ontological shifts’. Humans 1000 years ago might have said God was good, nothing else (though really they loved friendships and stories and games and food as well). Those morals didn’t survive scientific and intellectual progress. So maybe AI values will be alien to us due to similar shifts?
- But if humans remain in control, their values might also shift as they learn more (as they have in the past). So I think this point is over-egged.
Still, overall I think that conditioning on takeover pushes towards being more concerned about AI takeover.
Conditioning on the human actually seizing power
But there are also reasons to think human takeover could be especially bad:
- Human variance is also high. Even though they don’t vary as much as AI systems might, humans still vary massively in how moral they are. And I think it’s a pretty self-obsessed dark-triad kind of person that might ultimately seize power for themselves and a small group. So the human left-tail in my graph could be pretty long, and the selection effect for taking over could be very strong. Humans in power have done terrible things.
- However, humans (e.g. dark triad) are often bad people for instrumental reasons. But if you’re already the world leader and have amazing technology and material abundance, there’s less instrumental reason to mess others around. This might mean that a human who takes over acts more morally once they’ve cemented power.
- Humans are more likely to be evil. Humans are more likely to do literally evil things due to sadism or revenge. S-risk stuff. If AI has alien values it wouldn't do this, and we'll try to avoid actively incentivising these traits in AI training.
Other considerations
- Humans are less competent. Humans are more likely to do massively dumb (and harmful) things – like messing up commitment games, threats, simulations, and VHW stuff. I expect AI systems who seize power would have to be extremely smart and would avoid dumb and hugely costly errors. I think this is a very big deal.
- Some humans may not care about human extinction per se.3
- Extrapolating HHH training is overly optimistic:
- I’ve based some of the above on extrapolating from today’s AI systems, where RLHF focuses predominantly on giving AIs personalities that are HHH (helpful, harmless and honest) and generally good by human (liberal Western!) moral standards. To the extent these systems have goals and drives, they seem to be pretty good ones. That falls out of the fine-tuning (RLHF) data.
- But future systems will probably be different. Internet data is running out, and so a very large fraction of agentic training data for future systems may involve completing tasks in automated environments (e.g. playing games, SWE tasks, AI R&D tasks) with automated reward signals. The reward here will pick out drives that make AIs productive, smart and successful, not just drives that make them HHH.
- Examples drives:
- Having a clear plan for making progress
- Making progress minute by minute
- Making good use of resources
- Writing well organised code
- Keeping track of whether the project is on track to succeed
- Avoiding doing anything that isn’t strictly necessary for the task at hand
- A keen desire to solve tricky and important problems
- An aversion to the time shown on the clock implying that the task is not on track to finish
- These drives/goals look less promising if AI takes over. They look more at risk of leading to AI systems that would use the future to do something mostly without any value from a human perspective.
- Even if these models are fine-tuned with HHH-style RLHF at the end, the vast majority of fine-tuning will be from automated environments. So we might expect most AI drives to come from such environments (though the order of fine-tuning might help to make AIs more HHH despite the data disparity – unclear!).
- We’re still talking about a case where AI systems have some HHH fine-tuning, and so we’d expect them to care somewhat about HHH stuff, and wouldn’t particularly expect them to have selfish/immoral drives (unless they are accidentally reinforced during training due to a bad reward signal). So these AIs may waste large parts of the future, but I’d expect them to have a variety of goals/drives and still create large amounts of value by human lights.
- Interestingly, the fraction of fine-tuning that is HHH vs “amoral automated feedback from virtual environments” will probably vary by the industry in which the AI is deployed. AI systems working in counselling, caring, education, sales, and interacting with humans will probably be fine-tuned on loads of HHH-style stuff that makes them kind, but AI systems that don’t directly provide goods/services to humans (e.g. consulting, manufacturing, R&D, logistics, engineering, IT, transportation, construction) might only have a little HHH fine-tuning.
- Another interesting takeaway here is that we could influence the fine-tuning data that models get to make them more reinforcing of HHH drives. I.e. rather than having a AI SWE trained on solo-tasks in a virtual environment and evaluated with a purely automated signal for task-success, have it trained in a virtual company where it interacts with colleagues and customers and has its trajectories occasionally evaluated with process-based-feedback for whether it was HHH. Seems like this would make the SWE engineer more likely to have HHH drives, less likely to try to takeover, and more likely to create a good future if it did take over.
Overall, I’m honestly leaning towards thinking AI takeover would be less bad than human takeover.
Thanks to Lukas Finvedden, Marius Hobbhahn, Daniel Kokotajlo and Carl Shulman for early comments; the commenters on LessWrong for their input; and Max Dalton and Rose Hadshar for late stage review.
