Design sketches: defense-favoured coordination tech
Citations
5th April 2026


Intro
We think that near-term AI could make it much easier for groups to coordinate, find positive-sum deals, navigate tricky disagreements, and hold each other to account.
Partly, this is because AI will be able to process huge amounts of data quickly, making complex multi-party negotiations and discussions much more tractable. And partly it’s because secure enough AI systems would allow people to share sensitive information with trusted intermediaries without fear of broader disclosure, making it possible to coordinate around information that’s currently too sensitive to bring to the table, and to greatly improve our capacity for monitoring and transparency.
We want to help people imagine what this could look like. In this piece, we sketch six potential near-term technologies, ordered roughly by how achievable we think they are with present tech:1
- Fast facilitation — Groups quickly surface key points of consensus views and disagreement, and make decisions everyone can live with.
- Automated negotiation — Complicated bargains are discovered quickly via automated negotiation on behalf of each party, mediated by trusted neutral systems which can find agreements.
- Arbitrarily easy arbitration — Disputes are resolved cheaply and quickly by verifiably neutral AI adjudicators.
- Background networking — People who should know each other get connected (perhaps even before they know to go looking), enabling mutually beneficial trade, coalition building, and more.
- Structured transparency for democratic oversight — Citizens hold their institutions to account in a fine-grained way, without compromising sensitive information.
- Confidential monitoring and verification — Deals can be monitored and verified, even when this requires sharing highly sensitive information, by using trusted AI intermediaries which can’t disclose the information to counterparties.
We also sketch two cross-cutting technologies that support coordination:
- AI delegates and preference elicitation — AI delegates can faithfully represent and act for a human principal, perhaps supported by customisable off-the-shelf agentic platforms that integrate across many kinds of tech.
- Charter tech — The technologies above, or other coordination technologies, are applied to making governance dynamics more transparent, making it easier to anticipate how governance decisions will influence future coordination, and design institutions with this in mind.
An important note is that coordination technologies are open to abuse. You can coordinate to bad ends as well as good, and particularly confidential coordination technologies could enable things like price-setting, crime rings, and even coup plots. Because the upsides to coordination are very high (including helping the rest of society to coordinate against these harms), we expect that on balance accelerating some versions of these technologies is beneficial. But this will be sensitive to exactly how coordination technologies are instantiated, and any projects in this direction need to take especial care to mitigate these risks.
We’ll start by talking about why these tools matter, then look at the details of what these technologies might involve before discussing some cross-cutting issues at the end.

Why coordination tech matters
Today, many positive-sum trades get left on the table, and a lot of resources are wasted in negative-sum conflicts. Better coordination capabilities could lead to very large benefits, including:
- Improving economic productivity across the board
- Helping nations avoid wars and other destructive conflicts
- Enabling larger groups to coordinate to avoid exploitation by a small few
- Making democratic governance much more transparent, while protecting sensitive information
What’s more, getting these benefits might be close to necessary for navigating the transition to more powerful AI systems safely. Absent coordination, competitive pressures are likely to incentivise developers to race forward as fast as possible, potentially greatly increasing the risks we collectively run. If we become much better at coordination, we think it is much more likely that the relevant actors will be able to choose to be cautious (assuming that is the collectively-rational response).
However, coordination tech could also have significant harmful effects, through enabling:
- AI companies to collude with each other against the interests of the rest of society2
- A small group of actors to plot a coup
- More selfishness and criminality, as social mechanisms of coordination are replaced by automated ones which don’t incentivise prosociality to the same extent
Regardless of how these harms and benefits net out for ‘coordination tech’ overall, we currently think that:
- The shape and impact of coordination tech is an important part of how things will unfold in the near term, and it’s good for people to be paying more attention to this.
- We’re going to need some kinds of coordination tech to safely navigate the AI transition.
- The devil is in the details. There are ways of advancing coordination tech which are positive in expectation, and ways of doing so which are harmful.
Why ‘defense-favoured’ coordination tech
That’s why we’ve called this piece ‘defense-favoured coordination tech’, not just ‘coordination tech’. We think generic acceleration of coordination tech is somewhat fraught — our excitement is about thoughtfully run projects which are sensitive to the possible harms, and target carefully chosen parts of the design space.
We’re not yet confident which the best bits of the space are, and we haven’t seen convincing analysis on this from others either. Part of the reason we’re publishing these design sketches is to encourage and facilitate further thinking on this question.
For now, we expect that there are good versions of all of the technologies we sketch below — but we’ve flagged potential harms where we’re tracking them, and encourage readers to engage sceptically and with an eye to how things could go badly as well as how they could go well.
Fast facilitation
Right now, coordinating within groups is often complex, expensive, and difficult. Groups often drop the ball on important perspectives or considerations, move too slowly to actually make decisions, or fail to coordinate at all.
AI could make facilitation much faster and cheaper, by processing many individual views in parallel, tracking and surfacing all the relevant factors, providing secure private channels for people to share concerns, and/or providing a neutral arbiter with no stake in the final outcome. It could also make it much more practical to scale facilitation and bring additional people on board without slowing things down too much.
Design sketch
An AI mediation system briefly interviews groups of 3–300 people async, presents summary positions back to the group, and suggests next steps (including key issues to resolve). People approve or complain about the proposal, and the system iterates to appropriate depth for the importance of the decision.
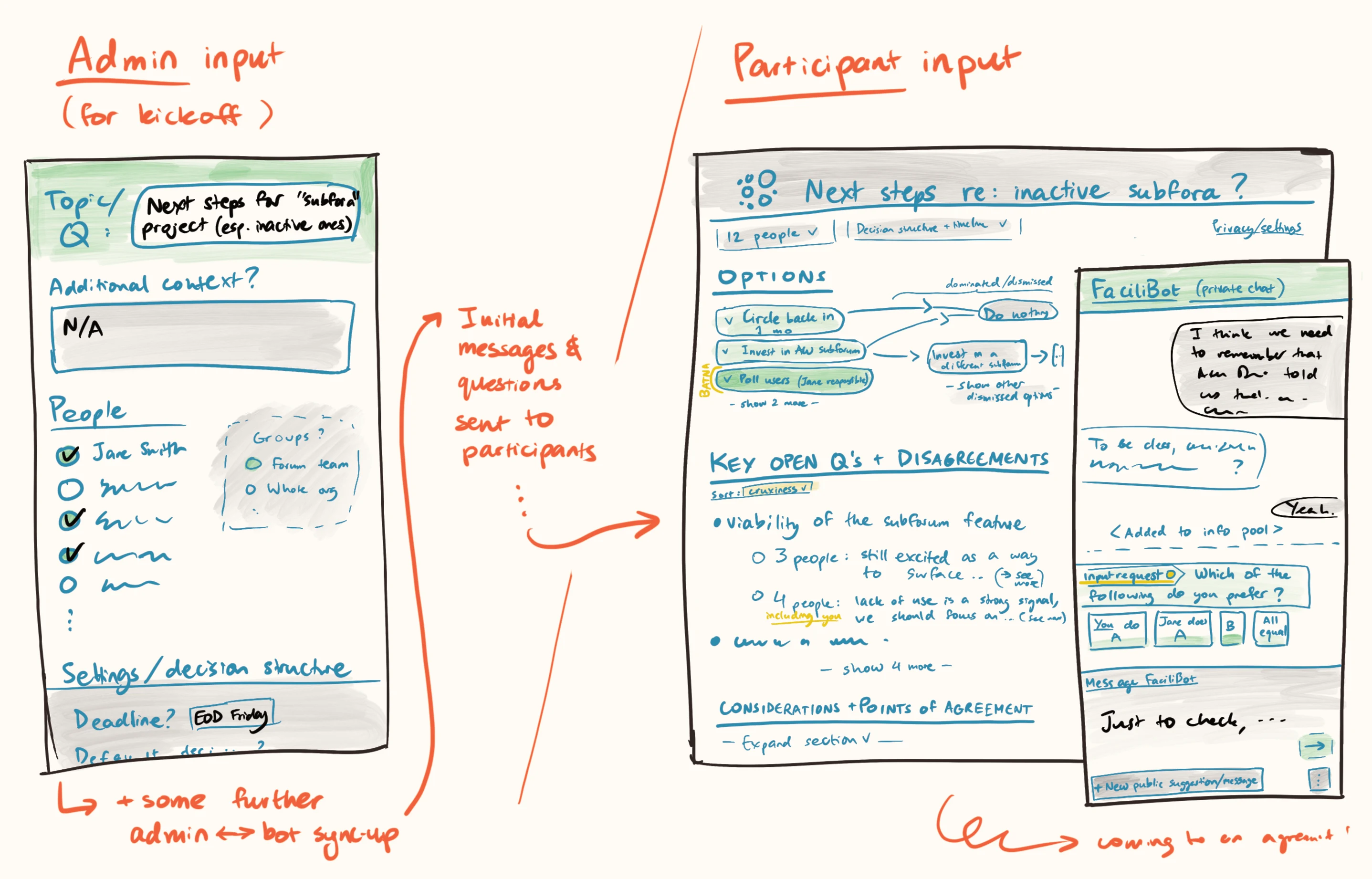
Image
Under the hood, it does something like:
- Gathers written context on the setting and decision
- Holds brief, private conversations with each participant to understand their perspective
- Builds a map of the issue at hand, involving key considerations and points of (dis)agreement
- Performs and integrates background research where relevant
- Identifies which people are most likely to have input that changes the picture
- Distils down a shareable summary of the map, and seeks feedback from key parties
- Proposes consensus statements or next steps for approval, iterating quickly to find versions that have as broad a backing as possible
Feasibility
Fast facilitation seems fairly feasible technically. The Habermas Machine (2024) does a version of this that provided value to participants — and we have seen two years of progress in LLMs since then. And there are already facilitation services like Chord. In general, LLMs are great at gathering and distilling lots of information, so this should be something they excel at. It’s not clear that current LLMs can already build accurate maps of arbitrary in-motion discourse, but they probably could with the right training and/or scaffolding.
Challenges for the technology include:
- Ensuring that it’s more efficient and a better user experience for moving towards consensus than other, less AI-based approaches.
- Remaining robust against abusive user behaviour (e.g. you don’t want individuals to get their way via prompt injection or blatantly lying).
Neither of these seem like fundamental blockers. For example, to protect against abuse, it may be enough to maintain transparency so that people can search for this. (Or if users need to enter confidential information, there might be services which can confirm the confidential information without revealing it.)
Possible starting points // concrete projects
- Build a baby version. This could help us notice obstacles or opportunities that would have been hard to predict in advance. You could focus on the UI or the tech side here, or try to help run pilots at specific organisations or in specific settings.
- Design ways to evaluate fast facilitation tools. This makes it easier to assess and improve on performance. For example, you could create games/test environments with clear “win” and “failure” modes.
- Build subcomponents. For example:
- Bots that surface anonymous info.
- Tools that try to surface areas of consensus or common knowledge as efficiently as possible, while remaining hard to game.
- Make a meeting prep system. Focus first on getting good at meeting prep — creating an agenda and considerations that need live discussion — to reduce possible unease about outsourcing decision-making to AI systems.
- Make a bot to facilitate discussions. This could be used in online community fora, or to survey experts.
- Design ways to create live “maps” of discussions. Fast facilitation is fast because it parallelises communication. This makes it more important to have good tools for maintaining shared context.

Automated negotiation
High-stakes negotiation today involves adversarial communication between humans who have limited bandwidth.
Negotiation in the future could look more like:
- You communicate your desires openly with a negotiation delegate who is on your side, asking questions only when needed to build a deeper model about your preferences.
- The delegate goes away, and comes back with a proposal that looks pretty good, along with a strategic analysis explaining the tradeoffs / difficulties in getting more.
Design sketch
Humans can engage AI delegates to represent them. The delegates communicate with each other via a neutral third party mediation system, returning to their principals with a proposal, or important interim updates and decision points.
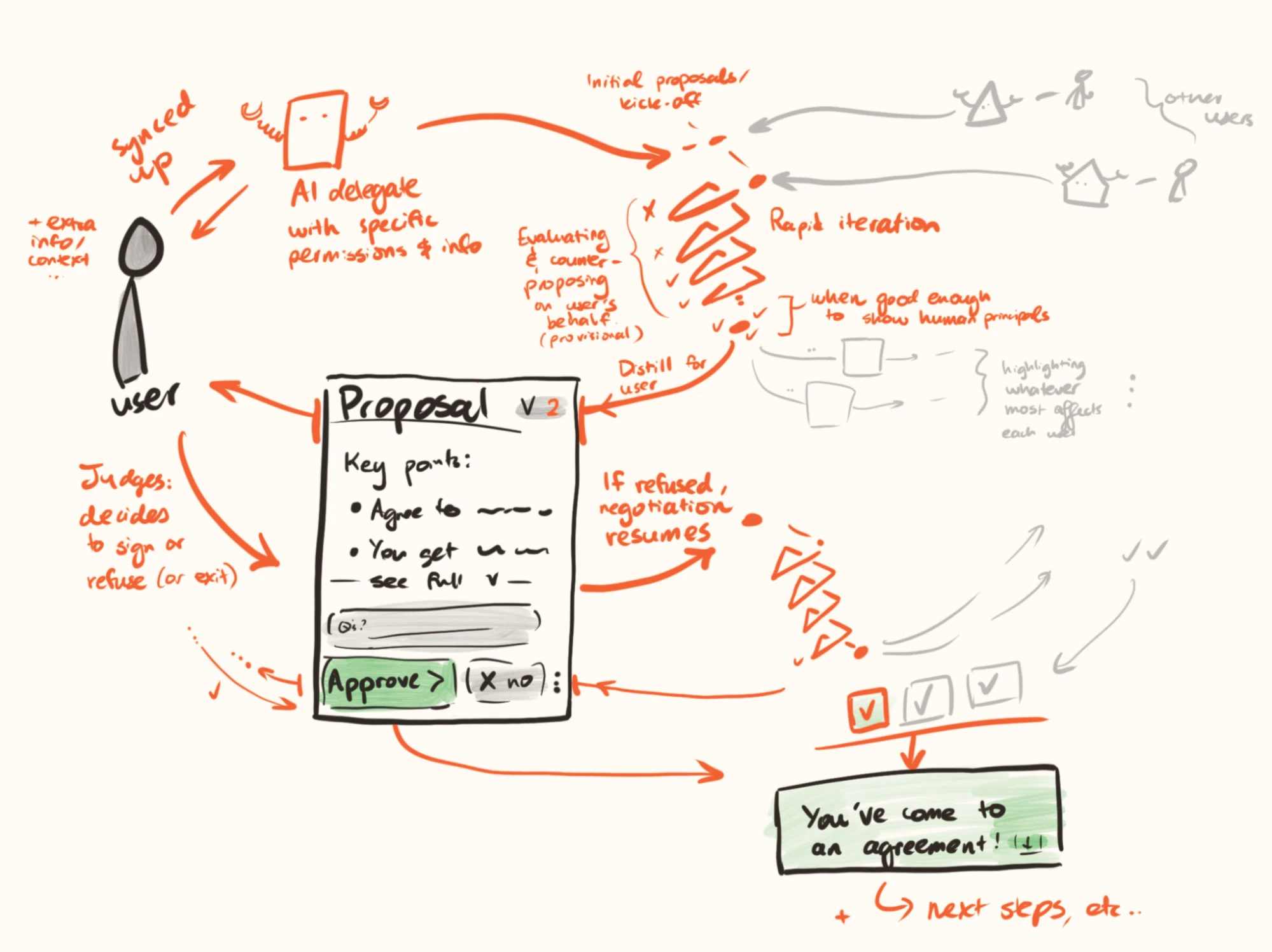
Image
Under the hood, this might look like:
- Delegate systems:
- Read over context documents and query principals about key points of uncertainty to build initial models of preferences.
- Model the negotiation dynamics and choose strategic approaches to maximise value for their principal.
- Go back to the principal with further detailed queries when something comes up that crosses an importance threshold and where they are insufficiently confident about being able to model the principal’s views faithfully.
- Are ultimately trained to get good results by the principal’s lights.
- Neutral mediator system:
- Is run by a trusted third-party (or in higher stakes situations, perhaps is cryptographically secure with transparent code).
- Discusses with all parties (either AI delegates, or their principals)
- Can hear private information without leaking that information to the other party
- Impossibility theorems mean that it will sometimes be strategically optimal for parties to misrepresent their position to the mediator (unless we give up on the ability to make many actually-good deals); however, we can seek a setup such that it is rarely a good idea to strategically misrepresent information, or that it doesn’t help very much, or that it is hard to identify the circumstances in which it’s better to misrepresent
- Searches for deals that will be thought well of by all parties, and proposes those to the delegates.
- Is ultimately trained to help all parties reach fair and desired outcomes, while minimising incentives-to-misrepresent for the parties.
Feasibility
Some of the technical challenges to automated negotiation are quite hard:
- The kind of security needed for high-stakes applications isn’t possible today.
- Getting systems to be deeply aligned with a principal’s best interests, rather than e.g. pursuing the principal’s short-term gratification via sycophancy, is an unsolved problem.
That said, it’s already possible to experiment using current systems, and it may not be long before they start improving on the status quo for human negotiation. Low-stakes applications don’t require the same level of security, and will be a great training ground for how to set up higher stakes systems and platforms. And practical alignment seems good enough for many purposes today.
Possible starting points // concrete projects
- Build an AI delegate for yourself or your friends. See if you can get it to usefully negotiate on your behalf with your friends or colleagues. Or failing that, if it can support you to think through your own negotiation position before you need to communicate with others about it.
- Build a negotiation app with good UI. Building on existing LLMs, build an app which helps people think through their negotiation position in a structured way. Focus on great UI.
- This could be non-interactive at first, and just involve communication between a human and the app, rather than between any AI systems.
- But it builds the muscles of a) designing good UI for AI negotiation, and b) people actually using AI to help them with negotiation.
- Run a pilot in an org or community you’re part of.
- You could start with fairly low-stakes negotiations, like what temperature to set the office thermostat to or which discussion topics to discuss in a given meeting slot.
- Experimenting with different styles of negotiation (in terms of how high the stakes are, how complex the structure is, and what the domain is) could be very valuable.

Arbitrarily easy arbitration
Right now, the risk of expensive arbitration makes many deals unreachable. If disputes could be resolved cheaply and quickly using verifiably fair and neutral automated adjudicators, this could unlock massive coordination potential, enabling a multitude of cooperative arrangements that were previously prohibitively costly to make.
Design sketch
An “Arb-as-a-Service” layer plugs into contracts, platforms, and marketplaces. Parties opt in to standard clauses that route disputes to neutral AI adjudicators with a well-deserved reputation for fairness. In the event of a dispute, the adjudicator communicates with parties across private, verifiable evidence channels, investigating further as necessary when there are disagreements about facts. Where possible, they auto-execute remedies (escrow releases, penalties, or structured commitments). Human appeal exists but is rarely needed; sampling audits keep the system honest. Over time, this becomes ambient infrastructure for coordination and governance, not just commerce.
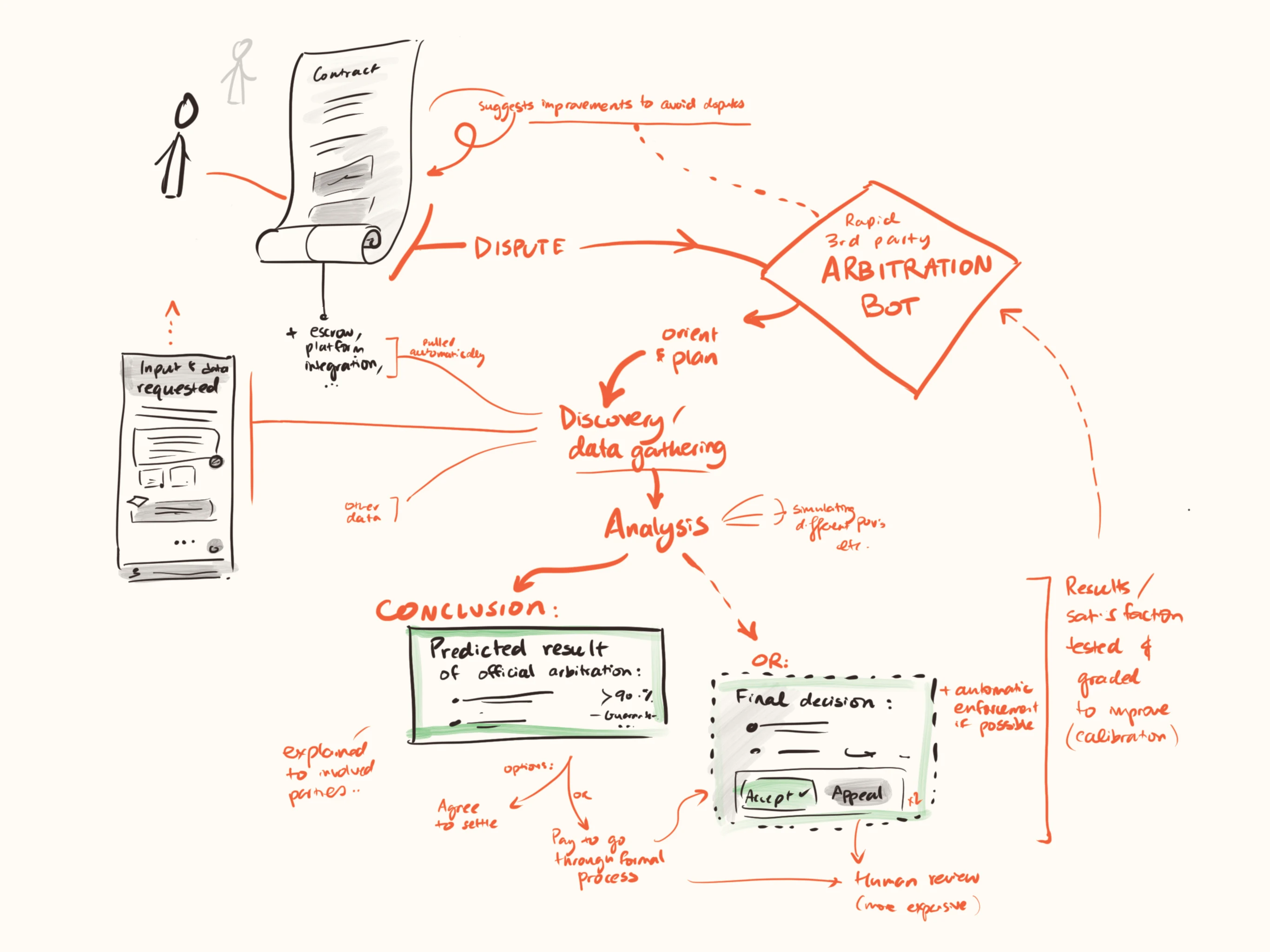
Image
How this could work under the hood:
- Agreement ingestion
- Formal or natural language contracts are parsed and key terms extracted, with parties confirming the system's interpretation before proceeding.
- The system could also suggest pre-dispute modifications to make agreements clearer, flag potentially unenforceable terms, and maintain public precedent databases that help parties understand likely outcomes before committing.
- Automated discovery
- When disputes arise, an automated discovery process gathers relevant documentation, transaction logs, and communications from integrated platforms.
- The system offers interviews and the chance to submit further evidence to each party.
- Deep consideration
- The system builds models of what different viewpoints (e.g. standard legal precedent; commonsense morality; each of the relevant parties) have to say on the situation and possible resolutions, to ensure that it is in touch with all major perspectives.
- Where there are disagreements, the system simulates debate between reasonable perspectives.
- It makes an overall judgement as to what is fairest.
- Transparent reasoning
- The system produces detailed explanations of its conclusions, with precedent citations and counterfactual analysis where appropriate.
- (Optional) Smart escrow integration
- Judgements automatically execute through cryptocurrency escrows or traditional payment rails, with graduated penalties for non-compliance.
- In cases where the system detects evidence that is highly likely to be fraudulent, or other attempts to manipulate the system, it automatically adds a small sanction to the judgement, in order to disincentivise this behaviour.
- Opportunities for appeal
- Either party can pay a small fee to submit further evidence and have the situation re-considered in more depth by an automated system.
- For larger fees they can have human auditors involved; in the limit they can bring things to the courts.
Feasibility
LLMs can already do basic versions of 1-4, but there are difficult open technical problems in this space:
- Judgement: Systems may not currently have good enough judgement to do 1, 3, 4 in high-stakes contexts (and until recently, they clearly didn’t).
- Real-world evidence assessment: Systems don’t currently know how to handle conflicting evidence provided digitally about what happened in the real world.
- Verifiable fairness/neutrality: The full version of this technology would require a level of fairness and neutrality which isn’t attainable today.
Those are large technical challenges, but we think it’s still useful to get started on this technology today, because iterating on less advanced versions of arbitration tech could help us to bootstrap our way to solutions. Particularly promising ways of doing that include:
- Starting in lower-stakes or easier contexts (for example, digital-only spaces avoid the challenge of establishing provenance for real-world evidence).
- Creating evals, test environments and other infrastructure that helps us improve performance.
On the adoption side, we think there are two major challenges:
- Trust: As above, some amount of technical work is needed to make systems verifiably fair/neutral. But even if it becomes true that the systems are neutral, people need to build quite a high level of confidence that the system is genuinely impartial before they'll bind themselves to its decisions for meaningful stakes.
- Legal integration: This tech is only useful to the extent that its arbitration decisions are recognised and enforced as legitimate by the traditional legal system, or are enshrined directly via contract in a self-enforcing way.
- (We are unsure how large a challenge this will be; perhaps you can write contracts today that are taken by the courts as robust. But it may be hard for parties to have large trust in them before they have been tested.)
Both of these challenges are reasons to start early (as there might be a long lead time), and to make work on arbitration tech transparent (to help build trust).
Possible starting points // concrete projects
- Work with an arbitration firm. Work with (or buy) a firm already offering arbitration services to start automating parts of their central work, and scale up from there.
- Work with an online platform that handles arbitration. Use AI to improve their processes, and scale from there.
- Create a bot to settle informal disputes. Build an arbitration-as-a-service bot that people can use to settle informal disputes.
- Trial a system on internal disputes. This could be at your own organisation, another organisation, or a coalition of early adopter organisations.
- Run a pilot in parallel to regular arbitration. Run a pilot where an automated arbitration system is given access to all the relevant information to resolve disputes, and reaches its own conclusions — in parallel to the regular arbitration process, which forms the basis of the actual decision. You could partner with an arbitration firm, or potentially do this through a coalition of early adopter organisations, perhaps in combination with philanthropic funding.

Background networking
We can only do things like collaborate, trade, or reconcile if we’re able to first find and recognise each other as potential counterparties. Today, people are brought into contact with each other through things like advertising, networking, even blogging. But these mechanisms are slow and noisy, so many people remain isolated or disaffected, and potentially huge wins from coordination are left undiscovered.3
Tech could bring much more effective matchmaking within reach. Personalised, context-sensitive AI assistance could carry out orders of magnitude more speculative matchmaking and networking. If this goes well, it might uncover many more opportunities for people to share and act on their common hopes and concerns.
Design sketch
A ‘matchmaking marketplace’ of attentive, personalised helpers bustles in the background. When they find especially promising potential connections, they send notifications to the principals or even plug into further tools that automatically take the first steps towards seriously exploring the connection.
You can sign up as an individual or an existing collective. If you just want to use it passively, you give a delegate system access to your social media posts, search profiles, chatbot history, etc. — so this can be securely distilled into an up-to-date representation of hopes, intent, and capabilities. The more proactive option is to inject deliberate ‘wishes’ through chat and other fluent interfaces.
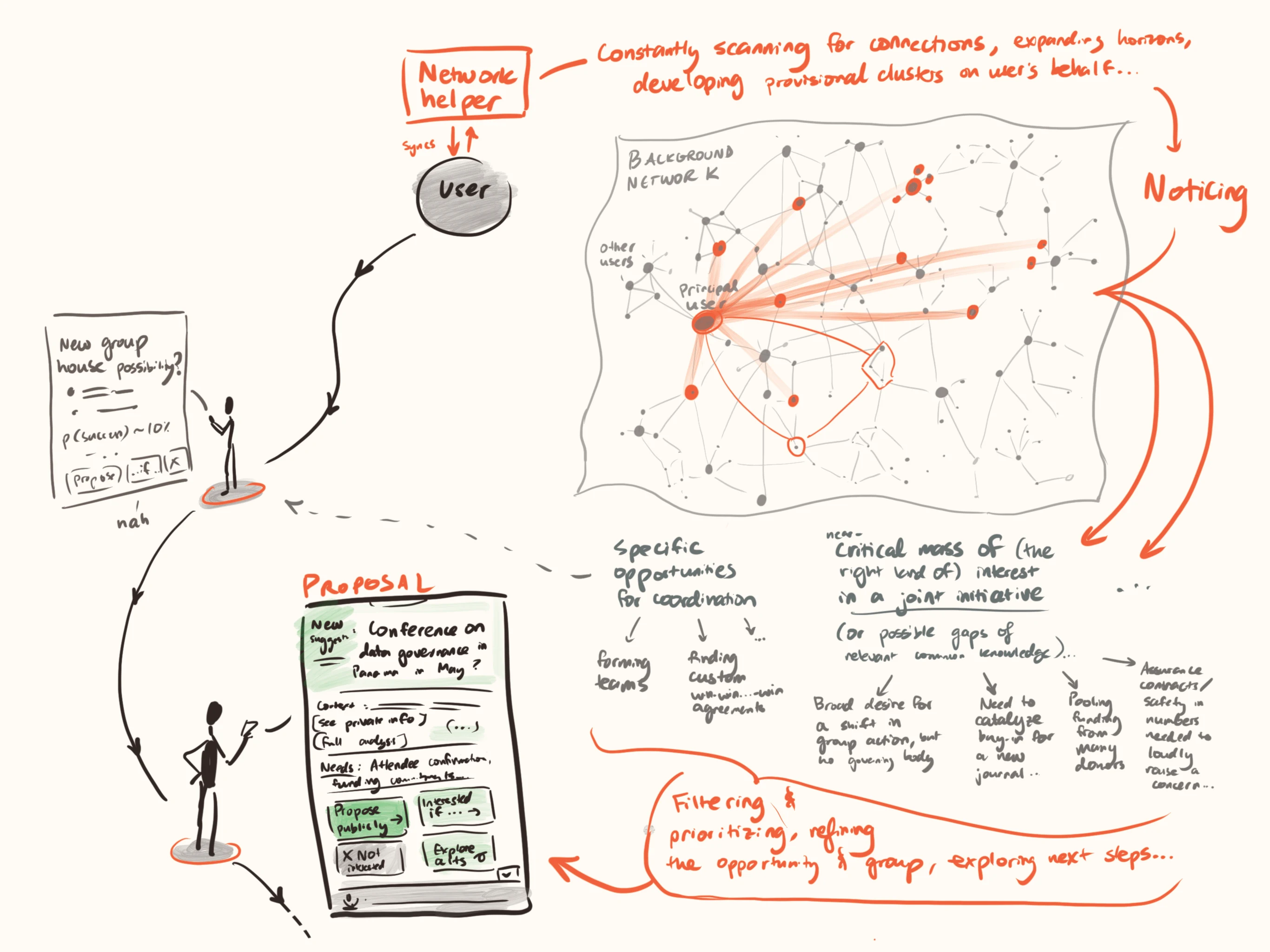
Image
Under the hood, there are a few different components working together:
- Interoperable, secure ‘wish profiling’ systems which identify what different participants want.
- People connect their profiles on existing services (social media, chatbot logs, email, etc).
- LLM-driven synthesis (perhaps combined with other forms of machine learning) curates a private profile of user desires.
- Optionally, chatbot-style assistance can interview users on the points of biggest uncertainty, to build a more accurate profile.
- A searchable ‘wish registry’ which organises large collections of wants and offers, while maintaining semi-privacy.
- Each user’s interests can run searches, finding potential matches and surfacing only enough information about them to know whether they are worth exploring further.
Feasibility
A big challenge here is privacy and surveillance. Doing background networking comprehensively requires sensitive data on what individuals really want. This creates a double-edged problem:
- If sensitive data is too broadly available, it can be used for surveillance, harassment, or exploitation; including by big corporations or states.
- If sensitive data is completely private, it opens up the possibility of collusion, for example among criminals.
This is a pretty challenging trade-off, with big costs on both sides. Perhaps some kind of filtering system which determines who can see which bits of data could be used to prevent data extraction for surveillance purposes while maintaining enough transparency to prevent collusion.
Ultimately, we’re not sure how best to approach this problem. But we think that it’s important that people think more about this, as we expect that by default, this sort of technology will be built anyway in a way that isn’t sufficiently sensitive to these privacy and surveillance issues. Early work which foregrounds solutions to these issues could make a big difference.
Other potential issues seem easier to resolve:
- Technically, background networking tools already seem within reach using current systems. Large-scale deployments would require indexing and registry, but it seems possible to get started on these using current systems.
- One note is that it seems possible to implement background networking in either a centralised or a decentralised way. It’s not clear which is best, though decentralised implementations will be more portable.
- Adoption also seems likely to work, because there are incentives for people to pay to discover trade and cooperation opportunities they would otherwise have missed, analogous to exchange or brokerage fees. Though there are some trickier parts, we expect them to ultimately be surmountable (though timing may be more up for grabs than absolute questions of adoption):
- In the early stages when not many people are using it, the value of background networking will be more limited. Possible responses include targeting smaller niches initially, and proactively seeking out additional network beneficiaries.
- It’s harder to incentivise people to pay for speculative things like uncovering groups they’d love that don’t yet exist. You could get around this using entrepreneurial or philanthropic speculation (compare the dominant assurance contract model and related payment incentivisation schemes).
Possible starting points // concrete projects
- Work with existing matchmakers to improve their offering. Find groups that are already doing matchmaking and are eager for better systems — perhaps among community organisers, businesses, recruiters or investors. Work with them to understand the pain points in their current networking, and what automated offerings would be most appealing. Then build those tools and systems.
- Build a networking tool for a specific community. Build a custom networking system for a particular group or subculture. For example, this could look like a networking app or a plug-in to an existing online forum. This could start delivering value fairly quickly, and provide a good opportunity for iteration.

Structured transparency for democratic oversight
Today, citizens in democracies have limited mechanisms to verify whether institutions' public claims are consistent with their internal evidence:
- The baseline is highly opaque.
- Freedom of information systems help, but can be evaded by non-cooperating institutions.
- Public inquiries can be reasonably thorough, but are expensive and slow.
- Full transparency has many costs and is typically highly resisted.
This is costly — e.g. the UK Post Office scandal over its Horizon IT system led to hundreds of wrongful prosecutions that could have been avoided. And it creates bad incentives for those running the institutions.
AI has the potential to change this. Instead of oversight being expensive, reactive, and slow, automated systems could in theory have real-time but sandboxed access to institutional data, routinely reviewing operational records against public claims and surfacing inconsistencies as they emerge.
Where confidential monitoring helps willing parties verify each other, structured transparency for democratic oversight aims to hold institutions accountable to the broader public.4
Design sketch
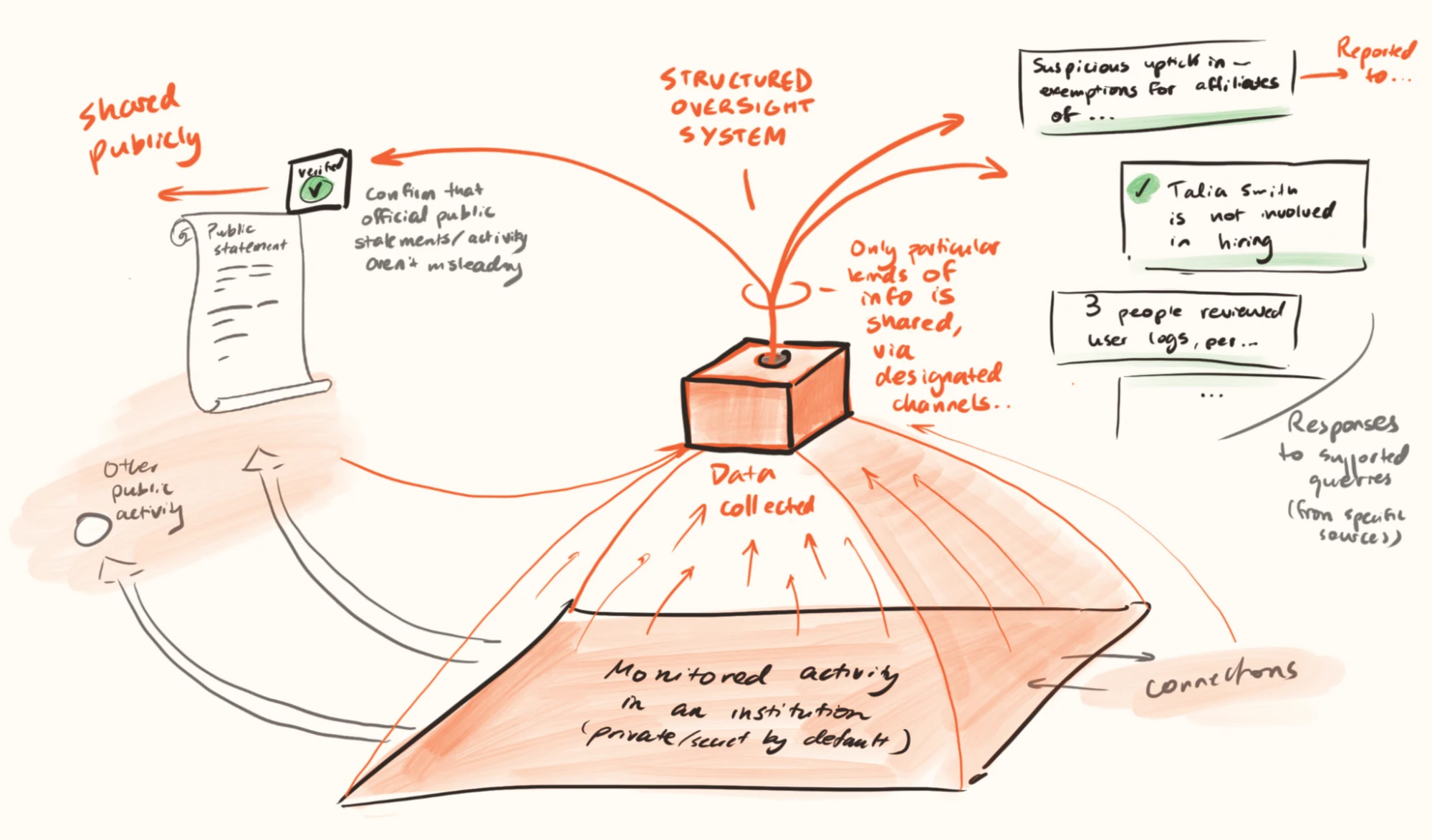
When an oversight body wants to verify facts about the behaviour of another institution, it requests comprehensive data about the internal operations of that institution. AI systems are tasked with careful analysis of the details, flagging the type and severity of any potential irregularities. Most of the data never needs human review.
In the simpler version, this is just a tool which expands the capacity of existing oversight bodies. Even here, the capacity expansion could be relatively dramatic — this kind of semi-structured data analysis is the kind of work that AI models can excel at today — without needing to trust that the systems are infallible (since the most important irregularities will still have human review).
A more ambitious version treats this as a novel architecture for oversight. AI systems operate continuously within secure environments that don’t give any humans access to the full dataset. They can flag inconsistencies as institutional data is deposited rather than waiting for an investigation to begin. For maximal transparency, summaries could be made available to the public in real-time, without revealing any confidential information that the public does not have rights to.
Image
Under the hood, this might involve:
- Secure data repositories, such that institutions routinely share operational data with a sandboxed environment operated by or on behalf of the oversight body, without any regular human access to the data.
- Continuous ingestion and indexing of institutional public outputs (press releases, regulatory filings, budget documents, etc.) into a searchable database.
- Automated cross-referencing between public claims and internal records.
- Highlighting of potential issues (mismatches between public statements and private information, as well as decisions made in violation of normal procedures).
- Further automated investigation of potential issues, leading to flags to humans in cases with sufficiently large issues flagged with sufficient confidence.
- Importantly, the sandbox outputs its findings but not the underlying data; if there is need for transparency on that, this is a separate oversight question.
Feasibility
There are two important aspects to feasibility here: technical and political.
Technically, decent reliability at the core functionality is possible today. Getting up to extremely high reliability so that it could be trusted not to flag too many false positives across very large amounts of data might be a reach with present systems; but is exactly the kind of capability that commercial companies should be incentivised to solve for business use.
Political feasibility may vary a lot with the degree of ambition. The simplest versions of this technology might in many cases simply be adopted by existing oversight bodies to speed up their current work. Anything which requires them getting much more data (e.g. to put in the sandboxed environments) might require legislative change — which may be more achievable after the underlying technology can be shown to be highly reliable.
Challenges include:
- Adversarial dynamics: the technical bar to verify claims against actively adversarial institutions (who are manipulating deposited data, potentially via AI) is substantially higher.
- This is the bar that we’d need to reach for confidential monitoring below.
- Defamation risk: the downsides of false positives, where your system reports someone misrepresenting things when they were not, could be significant (although can perhaps be mediated by giving people a right-of-rebuttal where they give further data to the AI systems which monitor the confidential data streams).
- Avoiding abuse: designing the systems so that they do not expose the confidential data, and cannot be weaponised to ruin the reputation of a department with very normal levels of error.
Ultimately the more transformative potential from this technology comes in the medium-term, with new continuous data access for oversight bodies. But this is likely to require legislative change, and the institutions subject to it may resist. Perhaps the most promising adoption pathway is to demonstrate value through voluntary pilots with oversight bodies that already have data access and want better tools. This could build the evidence base (and hence political constituency) for wider and deeper deployment.
Possible starting points // concrete projects
- Retrospective validation on historical cases. Apply consistency-checking tools to document sets from well-understood historical cases where the relevant internal documents have subsequently been released (e.g. Enron emails). This builds the technical foundation, and demonstrates the concept without requiring any current institutional access.
- Institutional public statement reliability tracker. Build a tool tracking whether agencies' public claims about performance, spending, or policy outcomes are consistent with publicly available data — statistical releases, budget documents, prior statements. Start with a single policy domain. This requires no institutional partnerships and builds a public constituency for structured transparency. This is a version of reliability tracking, applied specifically to institutional accountability.
- Pilot a FOIA exemption assessment tool. Partner with an Inspector General office to build a tool that reviews withheld documents and assesses whether claimed exemptions (national security, personal privacy, deliberative process) are applied appropriately. The IG already has legal access under the Inspector General Act; the tool helps them do their existing job faster and builds the working relationship needed for more ambitious deployments. This is also a natural testbed for the sandboxed architecture in miniature — the tool operates within the IG's secure environment, producing exemption-appropriateness findings without the documents themselves leaving the system.

Confidential monitoring and verification
Monitoring and verifying that a counterparty is keeping up their side of the deal is currently expensive and noisy. Many deals currently aren’t reachable because they’re too hard to monitor. Confidential AI-enabled monitoring and verification could unlock many more agreements, especially in high-stakes contexts like international coordination where monitoring is currently a bottleneck.
Design sketch
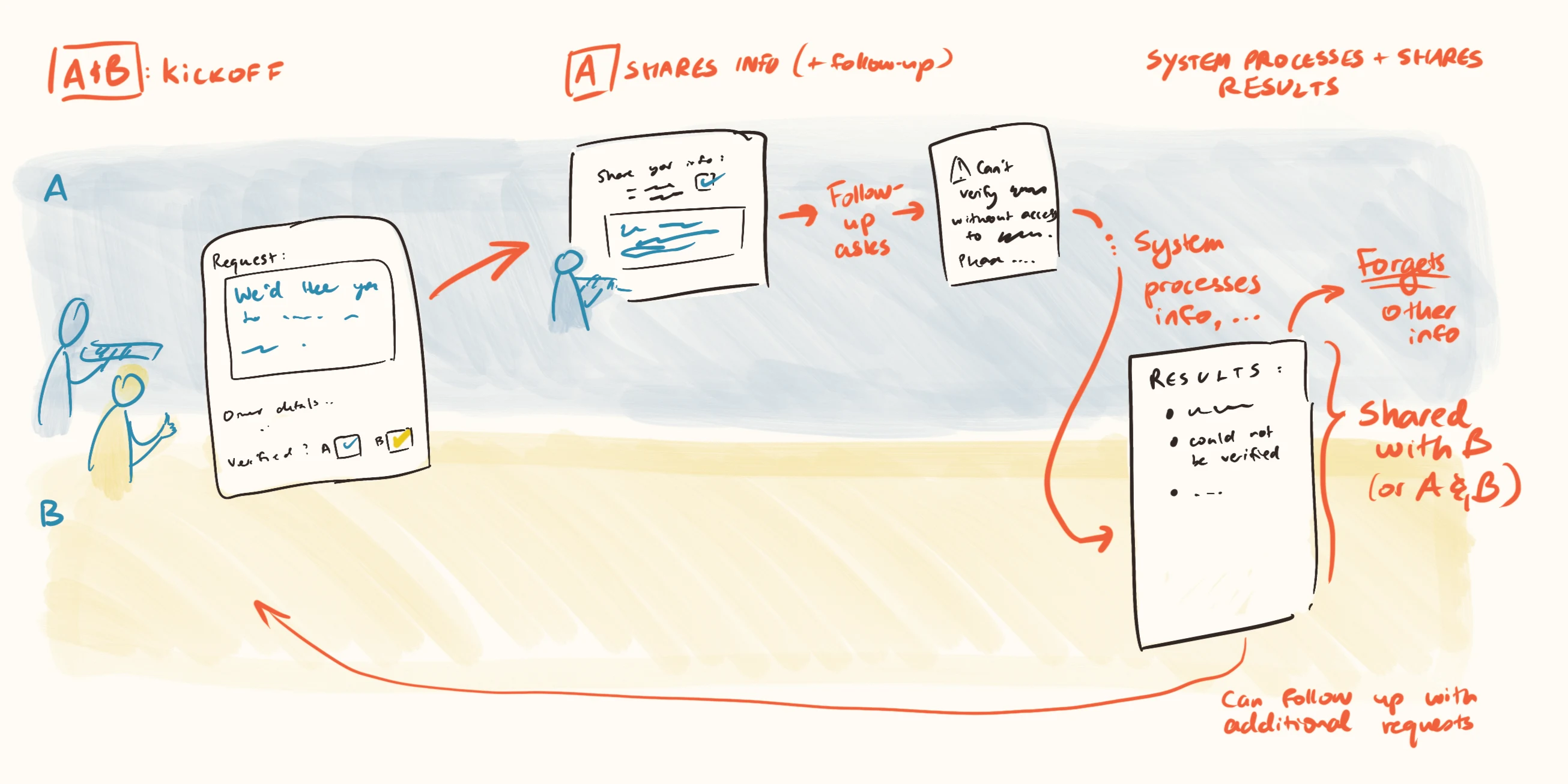
When organisation A wants to make credible attestations about their work to organisation B, without disclosing all of their confidential information, they can mutually contract an AI auditor, specifying questions for it to answer. The auditor will review all of A’s data (making requests to see things that seem important and potentially missing), and then produce a report detailing:
- Its conclusions about the specified questions.
- The degree to which it is satisfied that it had good data access, that it didn’t run into attempts to distort its conclusions, etc.
This report is shared with A and B, then A’s data is deleted from the auditor’s servers.
Image
Under the hood, this might involve:
- Building a Bayesian knowledge graph, establishing hypotheses, and understanding what evidence suggests about those hypotheses.
- Agentic investigatory probes into the confidential data, in order to form grounded assessments on the specified questions.
More ambitious versions might hope to obviate the need for trust in a third party, and provide reasons to trust the hardware — that it really is running the appropriate unbiased algorithms, that it cannot send side-channel information or retain the data, etc. Perhaps at some point you could have robot inspectors physically visiting A’s offices, interviewing employees, etc.
Feasibility
Compared to some of the other technologies we discuss, this feels technologically difficult — in that what’s required for the really useful versions of the tech may need very high reliability of certain types.
Nonetheless, we could hope to lay the groundwork for the general technological category now, so that people are well-positioned to move towards implementing the mature technology as early as is viable. Some low-confidence guesses about possible early applications include:
- Legal audits — for example, claims that the documents not disclosed during a discovery process are only those which are protected by privilege.
- Financial audits — e.g. for the purpose of proving viability to investors without disclosing detailed accounts.
- Supply chain verification — e.g. demonstrating that products were ethically sourced without exposing the suppliers.
Possible starting points // concrete projects
- Start building prototypes. Build a system which can try to detect whether it’s a real or counterfeited environment, and measure its success.
- Work with a law or financial auditing firm. Work with (or buy) a firm that does this kind of work, and experiment with how to robustly automate while retaining very high levels of trustworthiness.
- Explore the viability of complementary technology. For example, you could investigate the feasibility of demonstrating exactly what code is running on a particular physical computer that is in the room with both parties.
Cross-cutting thoughts
Some cross-cutting technologies
We’ve pulled out some specific technologies, but there’s a whole infrastructure that could eventually be needed to support coordination (including but not limited to the specific technologies we’ve sketched above). Some cross-cutting projects which seem worth highlighting are:
AI delegates and preference elicitation
Many of the technologies we sketched above either benefit from or require agentic AI delegates who can represent and act for a human principal. Developing customisable platforms could be useful for multiple kinds of tech, like background networking, fast facilitation, and automated negotiation.
Some ways to get started:
- Direct preference elicitation: develop efficient and appealing interview-style elicitation of values, wishes, preferences and asks.
- Passive data ingestion: build a tool that (consensually) ingests and distils all the available online content about a person — social media, browsing history, email, etc — and extracts principles from it (cf inverse constitutional AI).
One clarification is that though agentic AI delegates would be useful for some of the coordination tech above, it needn’t be the same delegate doing the whole lot for a single human:
- You could have different delegates for different applications.
- Some delegates might represent groups or coalitions.
- Some delegates could be short-lived, and spun up for some particular time-bounded purpose.
Charter tech
A lot of coordination effort between people and organisations goes not into making better object-level decisions, but establishing the rules or norms for future coordination — e.g. votes on changing the rules of an institution. It is possible that coordination tech will change this basic pattern, but as a baseline we assume that it will not. In that case, making such meta-level coordination go well would also be valuable.
One way to help it go well is by making the governance dynamics more transparent. Voting procedures, organisational charters, platform policies, treaty provisions, etc. create incentives and equilibria that play out over time, often in ways the framers didn't anticipate. Let’s call any technology which helps people to better understand governance dynamics, or to make those dynamics more transparent, ‘charter tech’. In some sense this is a form of epistemic tech; but as the applications are always about coordination, we have chosen to group it with other coordination technologies. We think charter tech could be important in two ways:
- Through directly improving the governance dynamics in question, helping to avoid capture, conflict, and lock-in.
- Through compounding effects on future coordination, which will unfold in the context of whatever governance structures are in place.
Charter tech could be used in a way that is complementary to any of the above technologies (if/when they are used for governance-setting purposes), although can also stand alone.
For the sake of concreteness, here is a sketch of what charter tech could look like:
- A “governance dynamics analyser” that ingests descriptions of constitutions, charters, policies or community norms, builds models of power, incentives, and information flow, and then (a) forecasts likely equilibria and failure modes, (b) red-teams for strategic abuse,5 and (c) proposes safer rule variants that preserve the framers’ intent.6
- While this tool can be called actively if needed, there is also a classifier running quietly in the background of organisational docs/emails, and when it detects a situation where power dynamics and governance rules are relevant, it runs an assessment — promoting this to user attention just in cases where the proposed rules are likely to be problematic.
Note that charter tech could be used to cause harm if access isn’t widely distributed. Vulnerabilities can be exploited as well as patched, and a tool that makes it easier to identify governance vulnerabilities could be used to facilitate corporate capture, backsliding or coups. Provided the technology is widely distributed and transparent, we think that charter tech could still be very beneficial — particularly as there may be many high-stakes governance decisions to make in a short period during an intelligence explosion, and the alternative of ‘do our best without automated help’ seems pretty non-robust.
Some ways to get started on using AI to make governance dynamics more transparent:
- Work with communities that iterate frequently on governance (DAOs, open-source projects) to test analyses against what actually happens when rules change.
- Compile a pattern library of governance failures and successes, documented in enough detail to inform automated analysis.
- Build simulation environments where proposed rules can be stress-tested against populations of agents with varying goals, including adversarial ones.
- Partner with mechanism design researchers to identify which aspects of their formal analysis can be automated and applied to less formal real-world documents.
Adoption pathways
Many of these technologies will be directly incentivised economically. There are clear commercial incentives to adopt faster, cheaper methods of facilitation, negotiation, arbitration, and networking.
However, adoption seems more challenging in two important cases:
- Adoption by governments and broader society. Many of the most important benefits of coordination tech for society will come from government and broad social adoption, but these groups will be less impacted by commercial incentives. This bites particularly hard for technologies that could be quite expensive in terms of inference compute, like fast facilitation, arbitration and negotiation. By default, these technologies might differentially help wealthy actors, leaving complex societal-level coordination behind. We think that the big levers on this set of challenges are:
- Building trust and legitimacy earlier, by getting started sooner, building transparently, and investing in evals and other infrastructure to demonstrate performance.
- Targeting important niches that might be slower to adopt by default. More research would be good here, but two niches that seem potentially important are:
- Coordination among and between very large groups, like whole societies. This might be both strategically important and lag behind by default.
- International diplomacy. Probably coordination tech will get adopted more slowly in diplomacy than in business, but there might be very high stakes applications there.
- Adoption of confidential monitoring and structured transparency. These technologies are less accessible with current models and may require large upfront investments, while many of the benefits are broadly distributed.
- This makes it less likely that commercial incentives alone will be enough, and makes philanthropic and government funding more desirable.
Other challenges
The big challenge is that coordination tech (especially confidential coordination tech) is dual use, and could empower bad actors as much or more than good ones.
There are a few ways that coordination tech could lead to shifts in the balance of power (positive or negative):
- Some actors could get earlier and/or better access to coordination tech than others.7
- Actors that face particular barriers to coordination today could be asymmetrically unblocked by coordination tech.
- Individuals and small groups could become more powerful relative to the coordination mechanisms we already have, like organisations, ideologies, and nation states.
It’s inherently pretty tricky to determine whether these power shifts would be good or bad overall, because that depends on:
- Value judgements about which actors should hold power.
- How contingent power dynamics play out.
- Big questions like whether ideologies or states are better or worse than the alternatives.
- Predictions about how social dynamics will equilibrate in an AI era that looks very different to our world.
However, as we said above, it’s clear that coordination tech might have significant harmful effects, through enabling:
- Large corporations to collude with each other against the interests of the rest of society.8
- A small group of actors to plot a coup.
- More selfishness and criminality, as social mechanisms of coordination are replaced by automated ones which don’t incentivise prosociality to the same extent.
We don’t think that this challenge is insurmountable, though it is serious, for a few reasons:
- The upsides are very large. Coordination tech might be close to necessary for safely navigating challenges like the development of AGI, and could empower actors to coordinate against the kinds of misuse listed above.
- The counterfactual is that coordination tech is developed anyway, but with less consideration of the risks and less broad deployment. We think that this set of technologies is going to be sufficiently useful that it’s close to inevitable that they get developed at some point. By engaging early with this space, we can have a bigger impact on a) which versions of the technology are developed, b) how seriously the downsides are taken by default, c) how soon these systems are deployed broadly.
- Some applications seem robustly good. For example, the potential for misuse is low for technologies like transparent facilitation or widely deployed charter tech. More generally, we expect that projects that are thoughtfully and sensitively run will be able to choose directions which are robustly beneficial.
That said, we think this is an open question, and would be very keen to see more analysis of the possible harms and benefits of different kinds of coordination tech, and which versions (if any) are robustly good.
This article has gone through several rounds of development, and we experimented with getting AI assistance at various points in the preparation of this piece. We would like to thank Anthony Aguirre, Alex Bleakley, Max Dalton, Max Daniel, Raymond Douglas, Owain Evans, Kathleen Finlinson, Lukas Finnveden, Ben Goldhaber, Ozzie Gooen, Hilary Greaves, Oliver Habryka, Isabel Juniewicz, Will MacAskill, Julian Michael, Justis Mills, Fin Moorhouse, Andreas Stuhmüller, Stefan Torges, Deger Turan, Jonas Vollmer, and Linchuan Zhang for their input; and to apologise to anyone we've forgotten.
Footnotes

Citations
Design sketches for a more sensible world
Article SeriesPart 4 of 4
We think that near-term AI systems could transform our ability to reason and coordinate, significantly improving our chances of safely navigating the transition to advanced AI systems. This sequence gives a series of design sketches for specific technologies that we think could help. We hope that these sketches make a more sensible world easier to envision, and inspire people to start building the relevant tech.